
NFS Datastores and what was their BIG issue…
• 0 Comments • ESX 3.5 Tips, ESXi 3.5 Tips, NetApp, Storage, VMware HA, VMware
This all started back about a year ago when I decided to move my datastores from Fibre Channel to NFS. The data was already on a NetApp FAS960c so I was enjoying thin provisioning and snapshots…but I wanted more!
We recently installed a new FAS6030 and was excited to try A-SIS (Data deduplication), so I decided that this was the perfect time to move all of our data over to the new filer and also change architectures and make the jump to NFS. I built out the vSwitch that has our VMKernel portgroup to include a few more NICs and proceeded to follow the NetApp & VMware VI3 Storage Best Practices Guide (TR3428).
Then I got to page number 9 (FYI, at the time this was version 3.1 of the document…I’ll get into why this is important later), where it proceeded to tell me to set NFS.LockDisable to 1 (0 is the default). Not really thinking anything about it I did it, which means I missed a unspoken Sys. Admin rule — always research suggested changes that could potentially affect other systems.
So, we were up and running…no cares or worries in the world! Everything was running great, I loved NFS and how easy it was to provision additional space on the fly, mount to other systems, etc…. (I still love it actually, it offers a ton of flexibility and there are a ton of cool things you can do to manage/backup/restore your data). It took almost a year but we had what appeared to be an outage, I couldn’t really put my finger on it at the time but VMware HA definitely kicked in (after doing some forensics after the fact I found that there wasn’t a hardware failure, actually one of our main core Cisco Switches did a spanning tree convergence which brought the entire network to a halt for roughly 25-30 seconds…JUST enough time for HA to think it was isolated).
So, what I found out from this little experience is that we crucially needed our NFS Locks to be in place and it was a VERY bad thing that we did by disabling them. What we saw happening is that all of the other primary nodes in the HA cluster (the first 4 hosts are primary by default) attempted to start the VMs when they thought the “node” failed. Ultimately it was very close to ALL of our VMs starting up on our first four hosts, and with locking disabled they were able to all start the VM and read/write the VMDK. Interestingly enough, NetApp removed the recommendation to set NFS.LockDisable=1 in a later revision of the TR3428 document.
So…why did NetApp initially recommend disabling NFS Locks? Well, in their initial testing the removal of VMware Snapshots took a long time over the NFS client (has to do with VMDK quiescing, lock removals, appending, etc… the one area NFS lacks because it is not a block level protocol). Their fix for the best practice guide was to remove NFS locks, but it sounds now like they didn’t do enough research before recommending this (and neither did I before implementing).
Until recently VMware has not had a fix for this “slow snapshot removal” issue, but thankfully they have released patch ESX350-200808401-BG which includes a fix just for that. But, it is a multi-step fix, so you will need to do the following;
1.) Download patch ESX350-200808401-BG.
2.) Identify an ESX server to apply the patch to.
3.) Using VMotion migrate the running VMs to other ESX nodes.
4.) Install this patch on the ESX server identified in step 2.
**5.) In the adv. configuration settings ensure that NFS file locking is enabled;
** _NFS.LockDisable=0
_
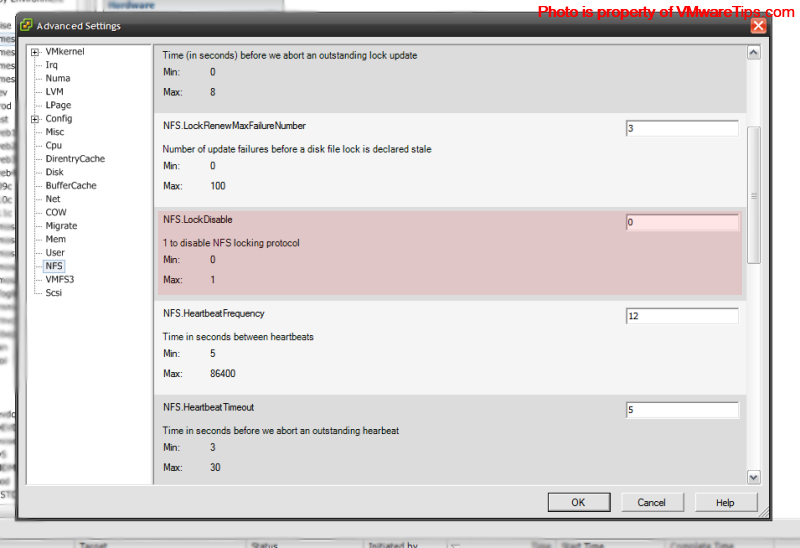
(Click on Image to Enlarge)
(this can also be done from the CLI with esxcfg-advcfg)
6.) Edit the following file: /etc/vmware/config file and add the line:
prefvmx.ConsolidateDeleteNFSLocks = “TRUE”
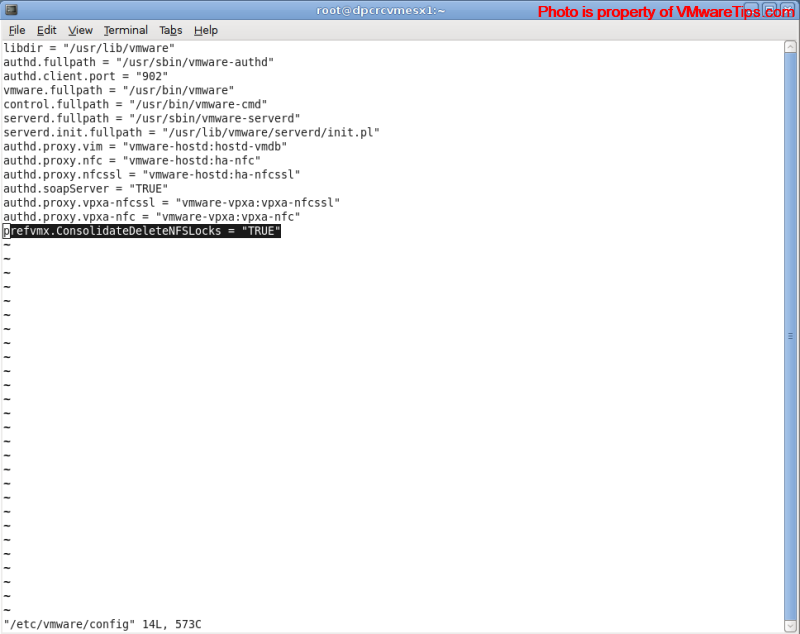
(Click on Image to Enlarge)
(For ESXi hosts, please read my blog on enabling service console access)
7.) Save the changes to the file.
8.) Reboot the ESX host.
9.) VMotion VMs back to patched/NFS lock enabled/prefvmx enabled host.
10.) Repeat steps 2 – 9 on each host in the cluster.
I’ve tested this and it does indeed return the .LCK files to my VMs and it also makes my snapshot removals very snappy.
For those of you that are interested in knowing what prefvmx.ConsolidateDeleteNFSLocks=TRUE actually does, here is a direct response from VMware;
“This changes the behavior of how locks are used while doing snapshot consolidations. [It] greatly improves performance of IO suspension- while maintaining file/data integrity of locking mechanism.”
So, good luck out there people. I know there are a lot of you that now have corrupt VMs because of the NFS.LockDisable issue. We just need to make sure people know of the above fix, and also refer to the latest Best Practice guide that NetApp provides, which is 4.2 (as of 10/13/2008) and can always be found here http://media.netapp.com/documents/tr-3428.pdf